RAG with local LLMs
Retrieval Augmented Generation with local LLMs
Project Overview
- Project Name : RAG with local LLMs
- Version : v1.0
- Last Modified : 09.09.2024
Thank you for taking the time to visit the RAG with local LLMs project! The project focuses on building a system capable of searching through PDF files containing work instructions, safety instructions, and departmental guidelines (approximately 1,000 PDFs) and answering user questions asked in natural language. By utilizing open-source language models, the company is not dependent on external providers such as OpenAI or Google, ensuring more control over data privacy and operational independence.
Methodologies




Method 1 - sentence-transformers with similarity search
The first method involved developing a script to parse data from PDF files using the pdfminer library. A structure was created that contained chunks of parsed text along with metadata describing each chunk, such as the number of tokens and other key characteristics.
The relevant chunks were then converted into embeddings using the sentence_transformers library, specifically employing the multi-qa-mpnet-base-dot-v1 model. These embeddings were stored in a torch.tensor structure, allowing for efficient storage and manipulation of the numerical representations of the text’s syntactic and semantic meaning.
For querying, an open-source LLaMA3 model was used in conjunction with a similarity search method to search through the embeddings and find the most relevant information. This enabled the language model to retrieve and provide the most accurate answers to the user’s questions.


Method 2 - llama-Index with ChromaDB
In this method, the llama-index library was used along with the LLaMA3 model for querying, and nomic-embed-text was utilized to generate embeddings. The PDF data was automatically parsed using the built-in methods of llama-index, and a vector database, ChromaDB, was created to index the embeddings generated by nomic-embed-text.
A query engine was then defined using LLaMA3, enabling the system to generate answers to user prompts based on the indexed data.
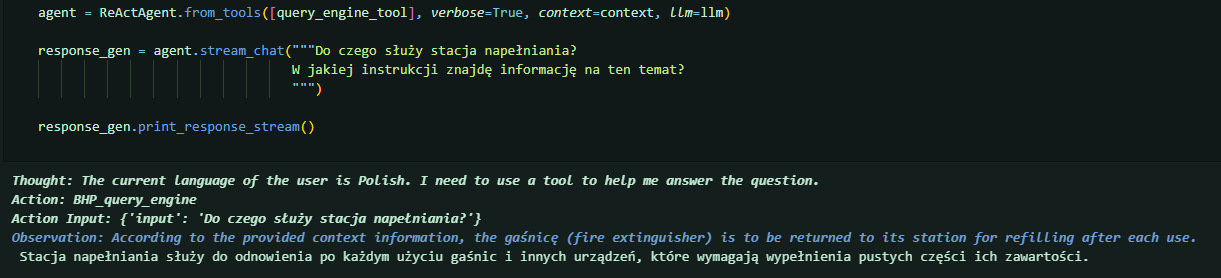
Method 3 - llama-Index agents with indexed embeddings
In this method, the data was parsed, and embeddings were calculated similarly to Method 2. The embeddings were then indexed in a StorageIndex, which was subsequently loaded into a QueryEngine.
The search engine was integrated into a ReAct agent from the llama-index library as a tool (function calling). This allowed users to ask questions to the LLaMA3 agent, who could generate the appropriate prompts for the query engine and respond to user inquiries based on the indexed data.
Summary
This project demonstrated the power and versatility of local language models and advanced document indexing techniques in creating a highly efficient system for information retrieval. The solution allowed for seamless navigation through vast amounts of complex data stored in thousands of PDF files, transforming previously static documents into an interactive resource for users.
By integrating local LLM models, the system provided fast and accurate responses to natural language queries, offering a user-friendly experience that was both intuitive and efficient. Furthermore, the use of open-source technologies enabled complete autonomy over the system's design and deployment, ensuring that sensitive company data remained secure and fully under the organization’s control.
The project's modular approach to embedding creation, data indexing, and query generation allowed for a scalable solution that could easily adapt to growing document sets and more sophisticated user requirements. It also laid the groundwork for future enhancements, including additional functionality and further optimization of search capabilities.